Capítulo 14. El DNA, el código genético y su traducción
Por muchos años, la genética
clásica se dedicó a estudiar los mecanismos de la herencia, a
dilucidar la manera en que las unidades hereditarias pasan de una generación
a la siguiente y a investigar cómo los cambios en el material hereditario
se expresan en los organismos individuales. En la década de 1930, surgieron
nuevas preguntas y los genetistas comenzaron a explorar la naturaleza del gen,
su estructura, composición y propiedades.
A comienzos de la década
de 1940, ya no quedaban dudas sobre la existencia de los genes ni sobre el hecho
de que estuviesen en los cromosomas. Ciertos científicos pensaban que
si se llegaba a comprender la estructura química de los cromosomas, entonces
se podría llegar a comprender su funcionamiento como portadores de la
información genética. Los primeros análisis químicos
del material hereditario mostraron que el cromosoma eucariótico está
formado por ácido desoxirribonucleico (DNA) y proteínas, en cantidades
aproximadamente iguales. Antes de conocerse cuál era, tanto el DNA como
las proteínas eran buenos candidatos para ser la molécula portadora
del material genético. Esta línea de pensamiento marcó
el comienzo de la vasta gama de investigaciones que conocemos como genética
molecular.
Ya avanzada la década
de 1940, algunos investigadores llegaron a una conclusión importante:
el material hereditario podía ser el ácido desoxirribonucleico
(DNA).
En 1953, los científicos
Watson y Crick reunieron datos provenientes de diferentes estudios acerca del
DNA. Sobre el análisis de esos datos, Watson y Crick postularon un modelo
para la estructura del DNA y fueron capaces de deducir que el DNA es una doble
hélice, entrelazada y sumamente larga.
Una propiedad esencial del material
genético es su capacidad para hacer copias exactas de sí mismo.
Watson y Crick supusieron que debía haber alguna forma en que las moléculas
de DNA pudiesen replicarse rápidamente y con gran precisión, de
modo que les fuese posible pasar copias fieles de célula a célula
y del progenitor a la descendencia, generación tras generación.
Watson y Crick propusieron un mecanismo para la replicación del DNA.
Dedujeron que la molécula de DNA se replica mediante un proceso semiconservativo
en el que se conserva la mitad de la molécula.
El modelo de Watson y Crick mostró de qué manera se podía
almacenar la información en la molécula de DNA.
A medida que avanzaban los años,
en la década de 1940, los biólogos comenzaron a notar que todas
las actividades bioquímicas de la célula viva dependen de ciertas
proteínas diferentes y específicas, las enzimas y que incluso
la síntesis de enzimas depende de enzimas. Más aun, se estaba
haciendo claro que la especificidad de las diferentes enzimas es el resultado
de la estructura primaria de estas proteínas, es decir, de la secuencia
lineal de aminoácidos que forman la molécula y que, a su vez,
determina mayormente su estructura tridimensional. Se comprobó que las
proteínas tenían una participación fundamental en todos
los procesos bioquímicos y esto promovió la realización
de estudios posteriores. Así, se demostró cuál es la relación
existe una relación entre genes y proteínas.
Como resultado de los estudios
realizados para dilucidar la relación entre DNA y proteínas hubo
un acuerdo general en que la molécula de DNA contiene instrucciones codificadas
para las estructuras y las funciones biológicas. Además, estas
instrucciones son llevadas a cabo por las proteínas, que también
contienen un "lenguaje" biológico altamente específico.
La cuestión entonces se convirtió en un problema de traducción:
¿de qué manera el orden de los nucleótidos en el DNA especifica
la secuencia de aminoácidos en una molécula de proteína?
La búsqueda de la respuesta a esta pregunta llevó a una importante
conclusión: el ácido ribonucleico (RNA) era un buen candidato
para desempeñar un papel en la traducción de la información.
Como se descubrió posteriormente,
no hay una, sino tres clases de RNA que desempeñan funciones distintas
como intermediarios en los pasos que llevan del DNA a las proteínas:
el RNA mensajero (mRNA), el RNA de transferencia (tRNa) y el RNA ribosomal (rRNA).
Los científicos de muchas disciplinas se abocaron a investigaciones dedicadas
a estudiar la correspondencia entre el lenguaje de nucleótidos en el
DNA y el lenguaje de aminoácidos en las proteínas. Así,
finalmente se dilucidó el código genético. Una vez conocido
el código genético, se pudo centrar la atención en el problema
de cómo la información codificada en el DNA y transcripta en el
mRNA es luego traducida a la secuencia específica de aminoácidos
en las proteínas. De esta manera, se establecieron los principios básicos
de la síntesis de proteínas. Estos principios son los mismos en
las células eucarióticas y en las procarióticas, pero hay
algunas diferencias en la localización de los procesos, además
de algunos detalles.
Hace casi 90 años, De
Vries definió la mutación en función de características
que aparecen en el fenotipo. A la luz del conocimiento actual, la definición
de mutación es algo diferente a la propuesta por de Vries: una mutación
es un cambio en la secuencia o número de nucleótidos en el DNA
de una célula.
En las décadas transcurridas
desde que fue descifrado el código genético, se han examinado
el DNA y las proteínas de muchos organismos. La evidencia actual es abrumadora:
el código genético es el mismo para virtualmente todos los seres
vivos, es decir, es universal. Sin embargo, recientemente se han encontrado
algunas pocas excepciones interesantes. El origen del código es el problema
de la biología evolutiva que nos deja más perplejos. La maquinaria
de traducción es tan compleja, tan universal y tan esencial que es difícil
imaginar cómo pudo haber surgido o cómo la vida puede haber existido
sin ella.
La pregunta por la química
de la herencia: ¿DNA o proteínas?
Los cromosomas, al igual que
todos los otros componentes de una célula viva, están formados
por átomos organizados en moléculas. Ciertos científicos
pensaron que resultaba imposible comprender la complejidad de la herencia basándose
en la estructura de compuestos químicos "sin vida". Los primeros
análisis químicos del material hereditario mostraron que el cromosoma
eucariótico está formado por ácido desoxirribonucleico
(DNA) y proteínas, en cantidades aproximadamente iguales. Por consiguiente,
ambos eran candidatos para desempeñar el papel de material genético.
Las proteínas parecían ser la elección más probable
por su mayor complejidad química. Las proteínas son polímeros
de aminoácidos, de los que existen 20 tipos diferentes en las células
vivas. Por contraste, el DNA es un polímero formado sólo por cuatro
tipos diferentes de nucleótidos.
Hasta la década de 1940,
muchos biólogos teóricos se apresuraron en señalar que
los aminoácidos, cuyo número era tan llamativamente cercano al
número de letras de nuestro alfabeto, podían disponerse en una
variedad de formas distintas; creían que los aminoácidos constituían
un lenguaje, "el lenguaje de la vida", que deletreaba las instrucciones
para las numerosas actividades de la célula. Muchos investigadores prominentes,
en particular los que habían estudiado proteínas, creían
que los genes mismos eran proteínas. Pensaban que los cromosomas contenían
modelos maestros de todas las proteínas que podría necesitar la
célula y que las enzimas y otras proteínas activas durante la
vida celular eran copiadas de estos modelos maestros. Esta era una hipótesis
lógica pero, según se vio posteriormente, errónea.
Los aminoácidos contienen un grupo amino (-NH2) y un grupo carboxilo (-COOH) unidos a un átomo de carbono central. Un átomo de hidrógeno y un grupo lateral están también unidos al mismo átomo de carbono. Esta estructura básica es idéntica en todos los aminoácidos. La "R" indica el grupo lateral, que es diferente en cada tipo de aminoácido. Los veinte aminoácidos que pueden constituir las proteínas. Como puede verse, la estructura esencial es la misma en las veinte moléculas, pero los grupos laterales difieren. Estos grupos pueden ser no polares (sin diferencia de carga entre distintas zonas del grupo), polares pero con cargas balanceadas de modo tal que el grupo lateral en conjunto es neutro, o cargados, negativa o positivamente. Los grupos laterales no polares no son solubles en agua, mientras que los grupos laterales polares y cargados son solubles en agua.
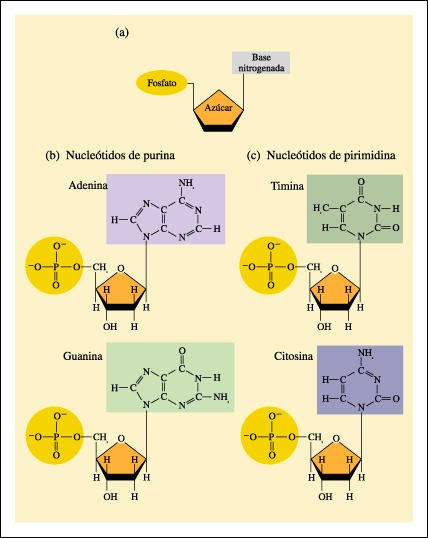
a) Un nucleótido está constituido por tres componentes diferentes: una base nitrogenada , un azúcar de cinco carbonos y un grupo fosfato. b) Los cuatro tipos de nucleótidos que se encuentran en el DNA. Cada nucleótido consiste en una de las cuatro bases nitrogenadas posibles, un azúcar desoxirribosa y un grupo fosfato.
El ácido desoxirribonucleico (DNA): el
material hereditario
Una evidencia importante del
papel del DNA como portador de la información genética, aunque
no aceptada generalmente, fue aportada por Frederick Griffith, un bacteriólogo
de salud pública de Inglaterra. Griffith estaba estudiando la posibilidad
de desarrollar vacunas contra Streptococcus pneumoniae, un tipo de bacteria
que causa una forma de neumonía. Como sabía Griffith, estas bacterias,
llamadas comúnmente neumococos, poseían formas virulentas -causantes
de la enfermedad- y formas no virulentas, o inocuas. Las virulentas estaban
cubiertas por una cápsula de polisacáridos y las no virulentas
carecían de cápsula. La producción de la cápsula
y su constitución son determinadas genéticamente, es decir, son
propiedades hereditarias de las bacterias.
El descubrimiento de la sustancia
que puede transmitir características genéticas de una célula
a otra resultó de los estudios con neumococos, las bacterias que causan
la neumonía. Una cepa de estas bacterias tiene cápsulas de polisacáridos
(cubiertas externas protectoras), y otra no. La capacidad para fabricar cápsulas
y causar la enfermedad es una característica heredada que pasa de una
generación bacteriana a otra, cuando las células se dividen.
Griffith realizó un experimento
con neumococos en el que primero (a) inyectó neumococos vivos encapsulados
a ratones y éstos murieron. En este caso (b) la cepa no encapsulada no
produjo infección. Si las bacterias encapsuladas eran muertas por la
aplicación de calor antes de la inyección (c), tampoco producían
infección. Si las bacterias encapsuladas muertas por calor se mezclaban
con bacterias vivas no encapsuladas, y la mezcla se inyectaba a los ratones
(d), éstos morían. Griffith tomó muestras de sangre de
los ratones muertos y las analizó (e). Los resultados revelaron la existencia
de neumococos encapsulados vivos.
"Algo" se había transferido de las bacterias muertas a las vivas que las dotaba de la capacidad para formar cápsulas de polisacáridos y causar neumonía. Este "algo" fue aislado; luego se encontró que era DNA.
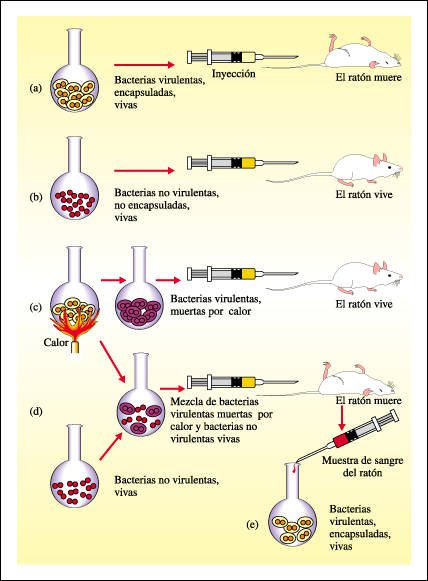
Experimento en el que se descubrió la sustancia que puede transmitir características genéticas de una célula a otra.
En 1940, los microbiólogos
Max Delbrück y Salvador Luria iniciaron una serie de estudios sobre el
papel del DNA usando un grupo de virus que atacan a las células bacterianas:
los bacteriófagos ("comedores de bacterias") o fagos, para
abreviar. Cada tipo conocido de célula bacteriana es atacado por un tipo
particular de virus bacteriano y, a su vez, muchas bacterias son hospedadores
de muchos tipos diferentes de virus. Veinticinco minutos después de que
un solo virus infectaba una célula bacteriana, esa célula estallaba,
liberando una centena o más de virus nuevos, todos copias exactas del
original. Otra ventaja (que no se descubrió hasta después de comenzada
la investigación) fue que este grupo de bacteriófagos tiene una
forma altamente distintiva que permite identificarlos fácilmente con
el microscopio electrónico.
El análisis químico
de los bacteriófagos reveló que consisten sencillamente en DNA
y proteína, los dos contendientes prominentes que se disputaban, en ese
momento, el papel de portador del material genético. La simplicidad química
del bacteriófago ofreció a los genetistas una oportunidad notable.
Los genes virales, el material hereditario que dirige la síntesis de
nuevos virus dentro de las células bacterianas, debían ser llevados
o bien por la proteína o bien por el DNA. Si podía determinarse
cuál de los dos contenía la información genética,
entonces podía conocerse la identidad química del gen.
Los científicos Hershey y Chase demostraron mediante un memorable experimento que la proteína es sólo un "envase" para el DNA del bacteriófago. Es el DNA del bacteriófago el que penetra en la célula y lleva el mensaje hereditario completo de la partícula viral, dirigiendo la formación de nuevo DNA viral y de las nuevas proteínas virales.
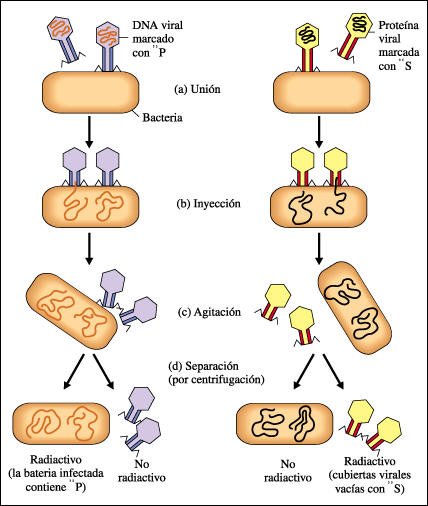
Resumen de los experimentos de Hershey y Chase que demostraron que el DNA es el material hereditario de un virus.
a) Luego de obtener los dos
tipos de virus (unos con el DNA marcado con fósforo y otros con las proteínas
marcadas con azufre) los científicos infectaron cultivos de bacterias
con ambos tipos de fagos marcados. Una vez infectadas (b),
las células se incubaron en un agitador (c) y luego fueron centrifugadas
para separarlas de cualquier material viral que permaneciera fuera de las células(d).
Las dos muestras, la que contenía material extracelular y la que contenía
material intracelular, se analizaron luego en busca de radiactividad. Hershey
y Chase encontraron que el 35S había permanecido
fuera de las células bacterianas, en las cubiertas virales vacías,
y que el 32P había entrado a las células, las había infectado
y había causado la producción de nueva progenie viral. Por consiguiente,
se concluyó que el material genético del virus era el DNA y no
la proteína.
El apoyo al papel del DNA como
material genético procedió también de otros datos adicionales:
1) Casi todas las células somáticas de cualquier especie dada
contienen cantidades iguales de DNA, y 2) Las proporciones de bases nitrogenadas
son las mismas en el DNA de todas las células de una especie dada, pero
varían en diferentes especies.
El modelo de Watson y Crick
James Watson y Francis Crick
se dedicaron a examinar y constrastar todos los datos existentes acerca del
DNA, y a unificarlos en una síntesis significativa.
En el momento en que Watson
y Crick comenzaron sus estudios, ya había un cúmulo de abundante
información.e sabía que la molécula de DNA era muy grande,
también muy larga y delgada, y que estaba compuesta de nucleótidos
que contenían las bases nitrogenadas adenina, guanina, timina y citosina.
Los físicos Maurice Wilkins
y Rosalind Franklin habían aplicado la técnica de difracción
de rayos X al estudio del DNA. Las fotografías obtenidas mostraban patrones
que casi con certeza reflejaban los giros de una hélice gigante.
También fueron cruciales
los datos que indicaban que, dentro del error experimental, la cantidad de adenina
(A) es igual que la de timina (T) y que la de guanina (G) es igual que la de
citosina (C): A=T y G=C.
A partir de estos datos, algunos
de ellos contradictorios, Watson y Crick intentaron construir un modelo de DNA
que concordara con los hechosconocidos
y explicara su papel biológico. Para llevar la gran cantidad de información
genética, las moléculas debían ser heterogéneas
y variadas.
Reuniendo los diferentes datos,
los dos científicos fueron capaces de deducir que el DNA es una doble
hélice, entrelazada y sumamente larga.
Si se tomase una escalera y se la torciera para formar una hélice, manteniendo
los peldaños perpendiculares, se tendría un modelo grosero de
la molécula de DNA. Los dos parantes o lados de la escalera están
constituidos por moléculas de azúcar y fosfato alternadas. Los
peldaños perpendiculares de la escalera están formados por las
bases nitrogenadas adenina, timina, guanina y citosina. Cada peldaño
está formado por dos bases, y cada base está unida covalentemente
a una unidad azúcar-fosfato. En la doble hélice, las bases enfrentadas
se aparean y permanecen unidas por puentes de hidrógeno, esos puentes
relativamente débiles que Pauling había encontrado en sus estudios
sobre la estructura de las proteínas. De acuerdo con las mediciones efectuadas
mediante rayos X, las bases apareadas (los peldaños de la escalera) debían
ser siempre combinaciones de una purina con una pirimidina.
Cuando Watson y Crick analizaron
los datos, armaron modelos reales de las moléculas usando alambre y hojalata,
ensayando dónde podía encajar cada pieza en el rompecabezas tridimensional.
A medida que trabajaban con los modelos, advirtieron que los nucleótidos
situados en cualquiera de las cadenas de la doble hélice podían
acoplarse en cualquier orden o secuencia. Dado que una molécula de DNA
puede tener miles de nucleótidos de largo, es posible obtener una gran
variedad de secuencias de bases diferentes, y la variedad es uno de los requisitos
primarios del material genético.
Notaron también que la cadena tiene dirección: cada grupo fosfato
está unido a un azúcar en la posición 5' -el quinto carbono
en el anillo de azúcar- y al otro azúcar en la posición
3' -el tercer carbono en el anillo de azúcar-. Así, la cadena
tiene un extremo 5' y un extremo 3'.
Sin embargo, el descubrimiento más excitante ocurrió cuando Watson
y Crick comenzaron a construir la cadena complementaria. Encontraron otra restricción
interesante e importante. No solamente las purinas no podrían aparearse
con purinas, ni las pirimidinas con pirimidinas, sino que, a causa de las estructuras
particulares de las bases, la adenina sólo podía aparearse con
la timina, formando dos puentes de hidrógeno (A=T) y la guanina solamente
con la citosina, formando tres puentes de hidrógeno (G=C). Las bases
apareadas eran complementarias.
Las dos cadenas corren en direcciones opuestas, es decir, la dirección desde el extremo 5' al 3' de cada cadena es opuesta y se dice que las cadenas son antiparalelas. Aunque los nucleótidos dispuestos a lo largo de una cadena de la doble hélice pueden presentarse en cualquier orden, su secuencia determina el orden de los nucleótidos en la otra cadena. Esto es necesariamente así, porque las bases son complementarias (G con C y A con T).
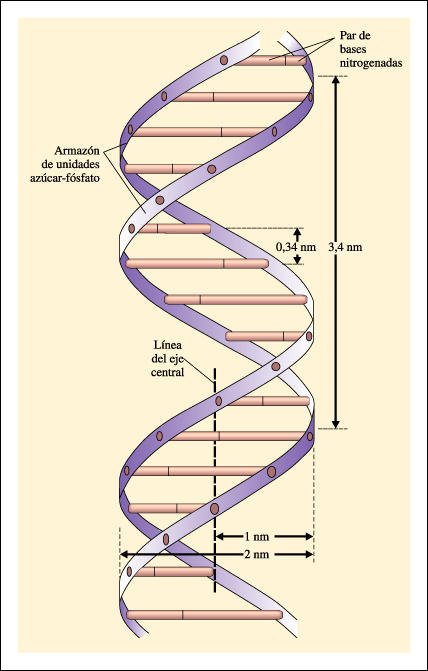
La estructura de doble hélice del DNA, como fue presentada en 1953 por Watson y Crick.
El armazón de la hélice está compuesto por las unidades
azúcar-fosfato de los nucleótidos. Los peldaños están
formados por las cuatro bases nitrogenadas, adenina y guanina (purinas) -cada
una de ellas con un anillo doble en su estructura- y timina y citosina (pirimidinas),
más pequeñas, cada una con un sólo anillo. Cada peldaño
está formado por dos bases. El conocimiento de las distancias entre los
átomos fue crucial para establecer la estructura de la molécula
de DNA. Las distancias fueron determinadas con fotografías de difracción
de rayos X del DNA, tomadas por Rosalind Franklin y Maurice Wilkins.
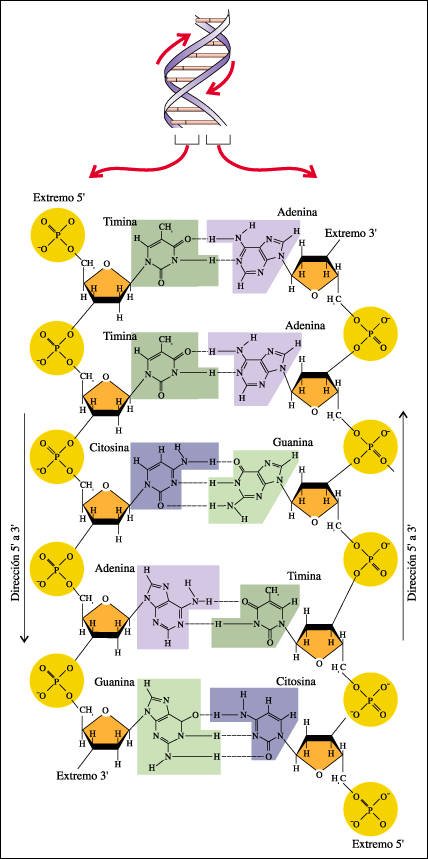
La estructura de doble cadena de una porción de una molécula de DNA.
En el modelo de Watson y Crick, cada nucleótido consiste en un azúcar
desoxirribosa, un grupo fosfato y una base púrica o pirimídica.
Nótese la secuencia repetida azúcar-fosfato-azúcar-fosfato
que forma el esqueleto de la molécula. Cada grupo fosfato está
unido al carbono 5' de una subunidad de azúcar y al carbono 3' de la
subunidad de azúcar del nucleótido contiguo. Así, la cadena
de DNA tiene un extremo 5' y un extremo 3' determinados por estos carbonos 5'
y 3'. La secuencia de bases varía de una molécula de DNA a otra.Las
cadenas se mantienen unidas por puentes de hidrógeno (representados aquí
por guiones) entre las bases. Nótese que la adenina y la timina pueden
formar dos puentes de hidrógeno, mientras que la guanina y la citosina
pueden formar tres. Dados estos requerimientos de enlace, la adenina puede aparearse
sólo con la timina y la guanina sólo con la citosina. Así,
el orden de las bases en una cadena -TTCAG- determina el orden de las bases
en la otra cadena -AAGTC. Las cadenas son antiparalelas, es decir, la dirección
desde el extremo 5' a 3' de una es opuesta a la de la otra.
La replicación del DNA
La replicación del DNA
comienza en una secuencia de nucleótidos particular en el cromosoma:
el origen de la replicación. Ocurre bidireccionalmente por medio de dos
horquillas de replicación que se mueven en direcciones opuestas. Las
enzimas helicasas desenrollan la doble hélice en cada horquilla de replicación
y proteínas de unión a cadena simple estabilizan las cadenas separadas.
Otras enzimas, las topoisomerasas, relajan el superenrollamiento de la hélice,
ya que cortan las cadenas por delante de las horquillas de replicación
y luego las vuelven a unir.
Para que pueda comenzar la replicación
se necesita una secuencia de cebador de RNA -sinetizado por la enzima RNA primasa-,
con sus bases correctamente apareadas con la cadena molde. La adición
de nucleótidos de DNA a la cadena es catalizada por las DNA polimerasas.
Estas enzimas sintetizan nuevas cadenas sólo en la dirección 5'
a 3', añadiendo nucleótidos uno a uno al extremo 3' de la cadena
creciente.
La replicación de la
cadena adelantada es continua, pero la replicación de la cadena rezagada
es discontinua. En la cadena rezagada, fragmentos de Okazaki se sintetizan en
la dirección 5' a 3'. La enzima DNA ligasa une fragmentos de Okazaki
contiguos. En el proceso de replicación del DNA se pierden nucleótidos
en los extremos de las moléculas de DNA lineales. En algunas células
eucarióticas, esta pérdida es compensada por la actividad de la
enzima telomerasa.
En el curso de la síntesis
de DNA, la DNA polimerasa corrige los errores, retrocediendo cuando es necesario
para eliminar nucleótidos que no estén correctamente apareados
con la cadena molde. Otros errores en el DNA ocurren en forma independiente
del proceso de replicación y son usualmente reparados por distintos mecanismos.
Los nucleótidos, antes de ser incorporados a las cadenas crecientes de DNA, se encuentran en forma de trifosfatos. La energía requerida para impulsar la replicación proviene de la eliminación de dos fosfatos "supernumerarios" y la degradación del enlace P ~ P.
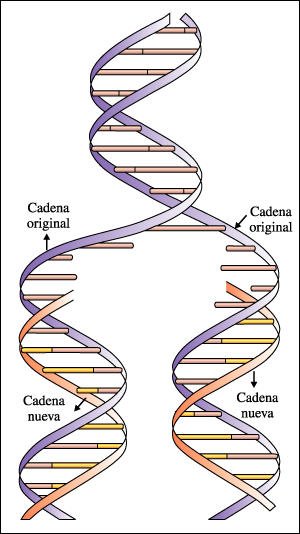
Replicación de la molécula de DNA, predicha por el modelo de Watson y Crick. Las cadenas se separan al romperse los puentes de hidrógeno que mantenían unidas a las bases. Cada una de las cadenas originales sirve luego como molde para la formación de una cadena complementaria nueva con los nucleótidos disponibles en la célula.
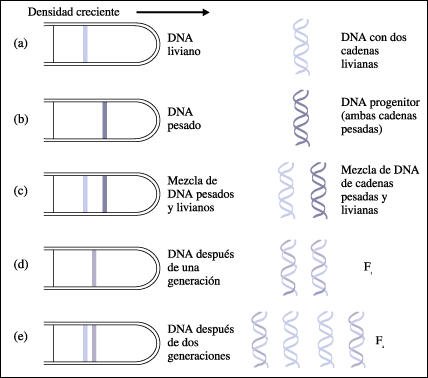
El experimento de Meselson y Stahl fue realizado para determinar que el modo de replicación del DNA era semiconservativo.
Meselson y Stahl realizaron
un experimento en el que comprobaron que: a) El DNA liviano normal forma una
banda ubicada en un lugar preciso cuando se ultracentrifuga en un gradiente
de densidad de cloruro de cesio. b) Células de E. coli cultivadas en
un medio con nitrógeno pesado (15N) acumulan un DNA pesado que, al ser
centrifugado en un gradiente de densidad, forma una banda separada y distinta.
c) Cuando se centrifuga una mezcla de DNA pesado y liviano en un gradiente de
densidad de cloruro de cesio, los dos tipos de DNA se separan en bandas distintas.
d) Cuando las células que fueron cultivadas en un medio con nitrógeno
pesado (15N) se multiplican durante una generación en un medio con nitrógeno
liviano común (14N), el DNA de las células hijas forma una banda
en el gradiente de densidad de cloruro de cesio que se localiza a mitad de camino
entre las bandas de DNA pesado y DNA liviano. e) Cuando las células que
contienen DNA pesado se cultivan durante dos generaciones en el medio con 14N,
el DNA de las células hijas forma dos bandas en el gradiente de densidad:
una banda de DNA liviano y una banda de DNA semipesado. La columna de la derecha
muestra las interpretaciones de los investigadores. Como se puede ver, este
experimento confirmó la hipótesis de Watson y Crick acerca de
que la replicación es semiconservativa.
Las dos cadenas de la doble
hélice de DNA se separan y sirven como moldes para la síntesis
de nuevas cadenas complementarias. Las helicasas, enzimas que operan en las
horquillas de replicación, separan las dos cadenas de la doble hélice
original. Las topoisomerasas, evitan el superenrollamiento, catalizando la formación
y resellado de cortes en una o ambas cadenas delante de las horquillas de replicación.
Las proteínas de unión a cadena simple estabilizan las cadenas
abiertas.
La DNA polimerasa cataliza la
adición de nucleótidos a ambas cadenas operando sólo en
dirección 5' a 3'. Para comenzar a añadir nucleótidos,
esta enzima requiere la presencia de un cebador de RNA, unido por puentes de
hidrógeno a la cadena molde que es luego reemplazado por nucleótidos
de DNA. El cebador de RNA es sintetizado por la RNA primasa.
La cadena adelantada se sintetiza
en la dirección 5' a 3' en forma continua. En este caso, el único
cebador de RNA está situado en el origen de replicación, que no
es visible en este esquema. La cadena rezagada también se sintetiza en
la dirección 5' a 3', a pesar de que esta dirección es opuesta
a la del movimiento de la horquilla de replicación. El problema se resuelve
mediante la síntesis discontinua de una serie de fragmentos, los fragmentos
de Okazaki. Cuando un fragmento de Okazaki ha crecido lo suficiente como para
encontrar a un cebador de RNA por delante de él, otra DNA polimerasa
reemplaza a los nucleótidos de RNA del cebador con nucleótidos
de DNA. Luego, la DNA ligasa conecta cada fragmento con el fragmento contiguo
recién sintetizado en la cadena.
El DNA como portador de información
El DNA de una sola célula
humana que, si se extendiera en una hebra única mediría casi 2
metros de largo, puede contener una información equivalente a unas 600.000
páginas impresas de 500 palabras cada una, o a una biblioteca de aproximadamente
1.000 libros.
Sin duda, la estructura del
DNA puede dar cuenta de la enorme diversidad de los seres vivos. La información
se encuentra en la secuencia de bases nitrogenadas y cualquier secuencia de
bases es posible. Dado que el número de pares de bases es de aproximadamente
5.000 en el virus más simple conocido, hasta una estimación de
5.000 millones en los 46 cromosomas humanos, el número de variaciones
posibles es astronómico.
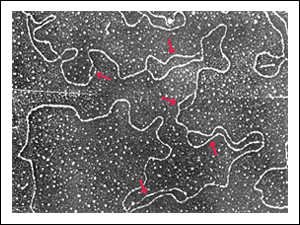
La replicación de los
cromosomas eucarióticos se inicia en orígenes múltiples.
Cada burbuja de replicación individual se extiende hasta que finalmente
se encuentra con otra y ambas se unen. En esta fotomicrografía electrónica
de una célula embrionaria de Drosophila melanogaster, los centros de
las burbujas de replicación están indicados con flechas.
Genes y proteínas
La relación entre genes
y proteínas es evidente en la actualidad. Sin embargo, cuando no estaba
todavía definida la relación entre ambas estructuras, se suscitaron
numerosas hipótesis. Los científicos Beadle y Tatum formularon
la propuesta -por entonces osada y luego ganadora del Premio Nobel- de que un
solo gen especifica una sola enzima o, en forma abreviada, "un gen-una
enzima".
Beadle y Tatum realizaron experimentos
en los que pudieron demostrar que un cambio en un solo gen da como resultado
un cambio en una sola enzima.
El procedimiento experimental
es el siguiente. a) Se extraen los ascos de los cuerpos fructíferos (ascocarpos)
de Neurospora y se sacan las esporas por disección. Estas esporas provienen
de cruzamientos entre cepas normales y cepas previamente sometidas a rayos X
para aumentar la tasa de mutación. b) Cada espora es transferida a un
medio enriquecido que contiene todo lo que la Neurospora necesita normalmente
para su crecimiento, además de aminoácidos suplementarios. c)
Se prueba la capacidad de un fragmento del moho para crecer en el medio mínimo.
Si no se observa crecimiento en el medio mínimo, puede haber ocurrido
una mutación que torna a este mutante incapaz de producir un aminoácido
particular. d) Se hacen subcultivos de los mohos que crecen en el medio enriquecido,
pero no en el medio mínimo. Se prueba su capacidad para crecer en medios
mínimos suplementados solamente con uno de los aminoácidos.
En el ejemplo que se muestra aquí, un moho que ha perdido la capacidad para sintetizar el aminoácido prolina es incapaz de sobrevivir en un medio que carece de este aminoácido. Luego se hacen pruebas para descubrir qué paso enzimático de la síntesis de la prolina fue bloqueado.
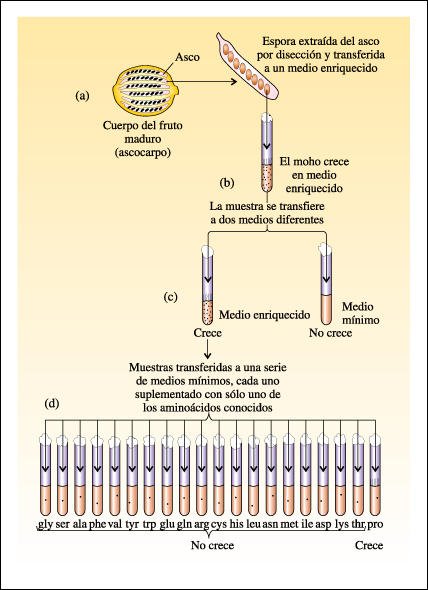
Procedimiento por el cual Beadle y Tatum analizaron los mutantes de Neurospora
Sin embargo, esto resultó
ser una sobresimplificación porque, aunque las enzimas son en verdad
proteínas, no todas las proteínas son enzimas. Algunas proteínas,
por ejemplo, son hormonas, como la insulina, y otras tienen función estructural,
como el colágeno. Como estas proteínas también son especificadas
por genes, se extendió el concepto original, pero no se modificó,
en principio. "Un gen-una enzima", fue simplemente corregido a "un
gen-una proteína". Posteriormente, al saberse que muchas proteínas
están formadas por más de una cadena polipeptídica, el
concepto se modificó una vez más al menos impactante, pero más
preciso, "un gen-una cadena polipeptídica". Más tarde,
este concepto también debió ser corregido.
Del DNA a la proteína:
el papel del RNA
Las moléculas de mRNA
son largas copias (o transcriptos) de secuencias de DNA -de 500 a 10.000 nucleótidos-
y de cadena simple pero, a diferencia de las moléculas de DNA, las de
RNA se encuentran en su mayoría como moléculas de cadena única.
Cada nueva molécula de mRNA se copia -o transcribe- de una de las dos
cadenas de DNA (la cadena molde) según el mismo principio de apareamiento
de bases que gobierna la replicación del DNA. A1 igual que una cadena
de DNA, cada molécula de RNA tiene un extremo 5' y un extremo 3'. Como
en la síntesis del DNA, los ribonucleótidos, que están
presentes en la célula como trifosfatos, se añaden uno por vez
al extremo 3' de la cadena en crecimiento de RNA. El proceso, conocido como
transcripción, es catalizado por la enzima RNA polimerasa. Esta enzima
opera de la misma forma que la DNA polimerasa, moviéndose en dirección
3' a 5' a lo largo de la cadena molde de DNA, sintetizando una nueva cadena
complementaria de nucleótidos -en este caso de ribonucleótidos-
en la dirección 5' a 3'. Así, la cadena de mRNA es antiparalela
a la cadena molde de DNA de la cual es transcripta.
La RNA polimerasa, a diferencia
de la DNA polimerasa, no requiere cebador para comenzar la síntesis de
RNA, ya que es capaz de iniciar una nueva cadena uniendo dos ribonucleótidos.
En procariotas, hay un único tipo de RNA polimerasa que, en realidad,
es un gran complejo multienzimático asociado con varias proteínas
que participan en diferentes momentos de la transcripción. Cuando va
a iniciar la transcripción, la RNA polimerasa se une al DNA en una secuencia
específica denominada secuencia promotora o promotor; abre la doble hélice
en una pequeña región y, así, quedan expuestos los nucleótidos
de una secuencia corta de DNA. Luego, la enzima va añadiendo ribonucleótidos,
moviéndose a lo largo de la cadena molde, desenrollando la hélice
y exponiendo así nuevas regiones con las que se aparearán los
ribonucleótidos complementarios. El proceso de elongación de la
nueva cadena de mRNA continúa hasta que la enzima encuentra otra secuencia
especial en el transcripto naciente, la señal de terminación.
En este momento, la polimerasa se detiene y libera a la cadena de DNA molde
y a la recién sintetizada cadena de mRNA.
El proceso de transcripción
del mRNA descripto para procariotas es similar en eucariotas, aunque presenta
algunas diferencias importantes. Entre ellas, se puede mencionar que, si bien
en procariotas las moléculas de mRNA se producen directamente por transcripción
del DNA, en eucariotas superiores, la mayor parte de los transcriptos sufren
un procesamiento posterior a la transcripción -llamado splicing del RNA-
antes de dejar el núcleo e ingresar al citoplasma.
El RNA mensajero transcripto a partir del DNA es, entonces, la copia activa de la información genética. Incorporando las instrucciones codificadas en el DNA, el mRNA dicta la secuencia de aminoácidos en las proteínas.
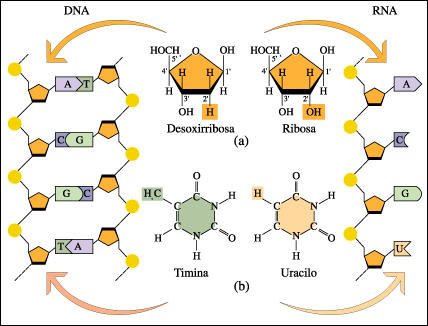
Diferencias entre el RNA y el DNA
Químicamente, el RNA es muy semejante al DNA, pero hay dos diferencias en sus nucleótidos. a) Una diferencia es el azúcar que lo compone. En lugar de desoxirribosa, el RNA contiene ribosa, en la cual el grupo hidroxilo reemplaza a un hidrógeno en el carbono 2'. b) La otra diferencia es que, en lugar de timina, el RNA contiene una pirimidina íntimamente relacionada con ésta, el uracilo (U). El uracilo, al igual que la timina, se aparea sólo con la adenina. Una tercera y muy importante diferencia entre los dos ácidos nucleicos es que, en la mayoría de los casos, el RNA se encuentra como cadena simple y no forma una estructura helicoidal regular como el DNA. A pesar de esto, como veremos más adelante, algunas moléculas de RNA presentan estructura secundaria, es decir, ciertas zonas de la molécula pueden formar bucles o encontrarse como doble cadena, por apareamiento de bases dentro de la misma molécula.
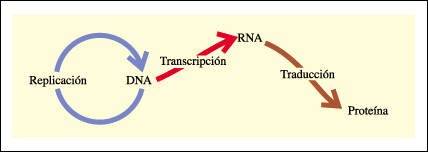
El "dogma" central de la genética molecular
El "dogma" central de la genética molecular: "La información fluye del DNA al RNA y de éste a las proteínas". La replicación del DNA ocurre sólo una vez en cada ciclo celular, durante la fase S previa a la mitosis o a la meiosis. La transcripción y la traducción, sin embargo, ocurren repetidamente a través de toda la interfase del ciclo celular. Nótese que, según este dogma, los procesos ocurren en una sola dirección. Una diversidad de experimentos han demostrado que se cumple, salvo algunas pocas excepciones. La principal excepción al dogma central es un proceso llamado transcripción inversa, en el cual la información codificada por ciertos virus que contienen RNA se transcribe a DNA por la acción de la enzima transcriptasa inversa.
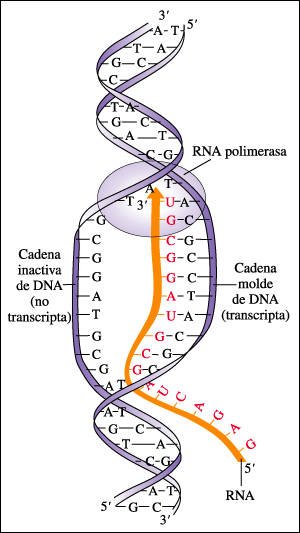
Representación esquemática de la transcripción del RNA.
En el punto de unión de la enzima RNA polimerasa, la doble hélice
de DNA se abre y, a medida que la RNA polimerasa se mueve a lo largo de la molécula
de DNA, se separan las dos cadenas de la molécula. Los ribonucleótidos,
que constituyen los bloques estructurales, se ensamblan en la dirección
5' a 3' a medida que la enzima lee la cadena molde de DNA en la dirección
3' a 5'. Nótese que la cadena de RNA recién sintetizada es complementaria,
no idéntica, a la cadena molde a partir de la cual se transcribe; su
secuencia, sin embargo, es idéntica a la cadena inactiva de DNA (no transcripta),
excepto en lo que respecta al reemplazo de timina (T) por uracilo (U). El RNA
recién sintetizado se separa de la cadena molde de DNA.
Código genético
El código genético
consiste en el sistema de tripletes de nucleótidos en el RNA -copiado
a partir de DNA- que especifica el orden de los aminoácidos en una proteína.
Las proteínas contienen
20 aminoácidos diferentes, pero el DNA y el RNA contienen, cada uno,
sólo cuatro nucleótidos diferentes. Si un solo nucleótido
"codificara" un aminoácido, entonces sólo cuatro aminoácidos
podían ser especificados por las cuatro bases nitrogenadas. Si dos nucleótidos
especificaran un aminoácido, entonces podría haber, usando todos
los arreglos posibles, un número máximo de 4 x 4, o sea 16 aminoácidos,
lo cual es insuficiente para codificar los veinte aminoácidos. Por lo
tanto, por lo menos tres nucleótidos en secuencia deben especificar cada
aminoácido. Esto resulta en 4 x 4 x 4, o sea, 64 combinaciones posibles
-los codones §- lo cual, claramente, es más que suficiente.
El código de tres nucleótidos,
o código de tripletes, fue ampliamente adoptado como hipótesis
de trabajo. Sin embargo, su existencia no fue realmente demostrada hasta que
el código fue finalmente descifrado, una década después
que Watson y Crick presentaran por primera vez su modelo de la estructura del
DNA.
El código genético
consiste en 64 combinaciones de tripletes (codones) y sus aminoácidos
correspondientes. Los codones que se muestran aquí son los que puede
presentar la molécula de mRNA. De los 64 codones, 6l especifican aminoácidos
particulares. Los otros 3 codones son señales de detención, que
determinan la finalización de la cadena. Dado que los 61 tripletes codifican
para 20 aminoácidos, hay "sinónimos" como, por ejemplo,
los 6 codones diferentes para la leucina.
La mayoría de los sinónimos, como se puede ver, difieren solamente en el tercer nucleótido. Sin embargo, la afirmación inversa no es válida: cada codón especifica solamente un aminoácido.
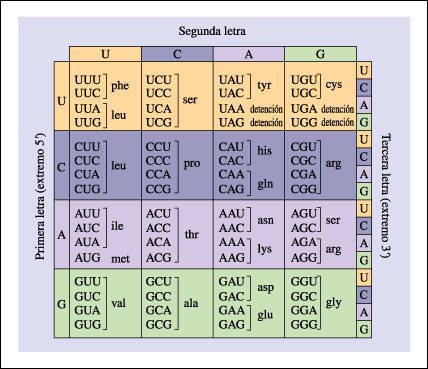
El código genético consiste en 64 combinaciones de tripletes (codones) y sus aminoácidos correspondientes.
La síntesis de proteínas o traducción
La síntesis de proteínas
ocurre en los ribosomas que consisten en dos subunidades, una grande y una pequeña,
cada una formada por rRNA y proteínas específicas. Para la síntesis
de proteínas, también se requiere de moléculas de tRNA,
que están plegadas en una estructura secundaria con forma de hoja de
trébol. Estas moléculas pequeñas pueden llevar un aminoácido
en un extremo y tienen un triplete de bases, el anticodón, en un asa
central, en el extremo opuesto de la molécula. La molécula de
tRNA es el adaptador que aparea el aminoácido correcto con cada codón
de mRNA durante la síntesis de proteínas. Hay al menos un tipo
de molécula de tRNA para cada tipo de aminoácido presente en las
células. Las enzimas conocidas como aminoacil-tRNA sintetasas catalizan
la unión de cada aminoácido a su molécula de tRNA específica.
En E. coli y otros procariotas,
aun cuando el extremo 3' de una cadena de mRNA está siendo transcripto,
se están uniendo ribosomas cerca de su extremo 5'. En el lugar donde
la cadena de mRNA está en contacto con un ribosoma, se unen tRNAs temporalmente
a la cadena de mRNA. Esta unión ocurre por apareamiento de bases complementarias
entre el codón de mRNA y el anticodón de tRNA. Cada molécula
de tRNA lleva el aminoácido específico requerido por el codón
de mRNA, al cual se une el tRNA. Así, siguiendo la secuencia dictada
originalmente por el DNA, las unidades de aminoácidos son alineadas una
tras otra y, a medida que se forman los enlaces peptídicos entre ellas,
se unen en una cadena polipeptídica.
Esquema general del flujo de información en procariotas y eucariotas: a) En procariotas, el RNA se transcribe a partir de una molécula de DNA circular y, a medida que ocurre la transcripción, se produce la traducción en el mismo compartimiento. b) En eucariotas, la transcripción ocurre en el núcleo y el RNA, luego de sufrir un procesamiento, se dirige al citoplasma donde se produce la síntesis de proteínas. Como se vio en el capítulo 5, algunas proteínas son sintetizadas en los ribosomas libres y otras en los que están adheridos al retículo endoplásmico.
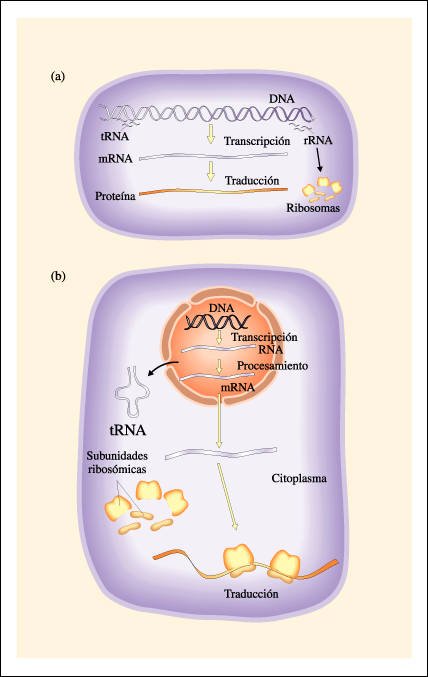
Esquema general del flujo de información en procariotas y eucariotas.
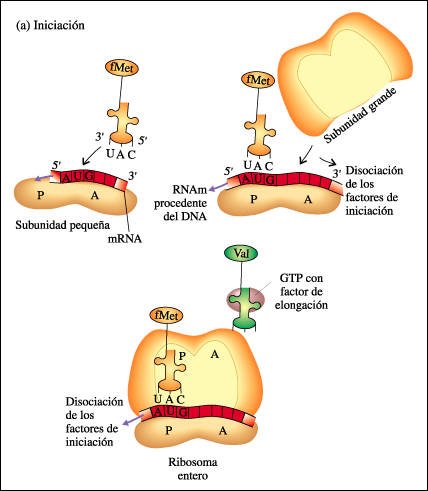
Tres etapas en la síntesis de proteínas en procariotas. a) Iniciación
La síntesis de proteínas ocurre en varias etapas: a) Iniciación.
La subunidad ribosómica más pequeña se une al extremo 5'
de una molécula de mRNA. La primera molécula de tRNA, que lleva
el aminoácido modificado fMet, se acopla con el codón iniciador
AUG de la molécula de mRNA. La subunidad ribosómica más
grande se ubica en su lugar, el complejo tRNA-fMet ocupa el sitio P (peptídico).
El sitio A (aminoacil) está vacante. El complejo de iniciación
está completo ahora.
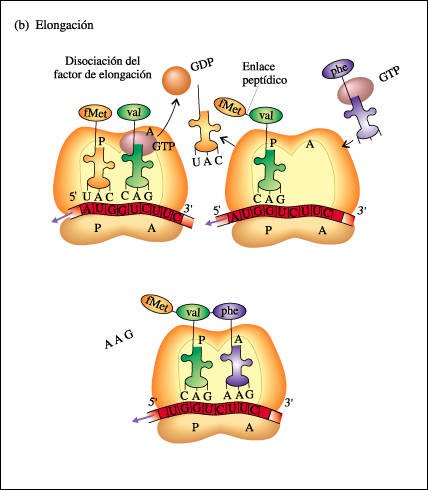
b) Elongación.
Un segundo tRNA, con su aminoácido unido, se coloca en el sitio A y su
anticodón se acopla con el mRNA. Se forma un enlace peptídico
entre los dos aminoácidos reunidos en el ribosoma. Al mismo tiempo, se
rompe el enlace entre el primer aminoácido y su tRNA. El ribosoma se
mueve a lo largo de la cadena de mRNA en una dirección 5' a 3', y el
segundo tRNA, con el dipéptido unido, se mueve desde el sitio A al sitio
P, a medida que el primer tRNA se desprende del ribosoma. Un tercer aminoacil-tRNA
se coloca en el sitio A y se forma otro enlace peptídico. La cadena peptídica
naciente siempre está unida al tRNA que se está moviendo del sitio
A al sitio P y el tRNA entrante que lleva el siguiente aminoácido siempre
ocupa el sitio A. Este paso se repite una y otra vez hasta que se completa el
polipéptido.
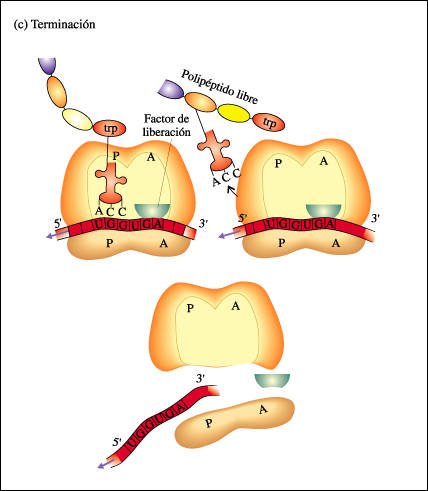
c) Terminación.
Cuando el ribosoma alcanza un codón de terminación (en este ejemplo UGA), el polipéptido se escinde del último tRNA y el tRNA se desprende del sitio P. El sitio A es ocupado por un factor de liberación que produce la disociación de las dos subunidades del ribosoma.
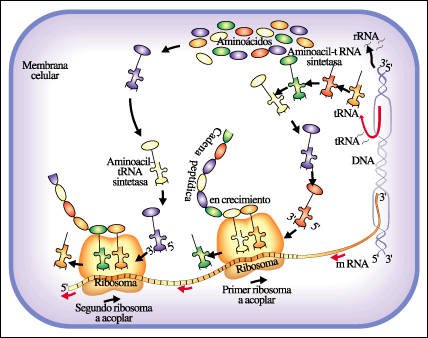
Resumen general de la síntesis de proteínas en una bacteria.
A partir del DNA cromosómico se transcriben: diferentes moléculas
de rRNA que, combinadas con proteínas específicas, forman los
ribosomas; los diferentes tipos de moléculas de tRNA correspondientes
a los distintos aminoácidos y los mRNA, que llevan la información
para la secuencia de aminoácidos de las proteínas. Cuando un mRNA
se une a la subunidad menor del ribosoma, comienza el proceso de síntesis
de proteínas, que se describe en detalle en el texto.
Redefinición de las mutaciones
En la actualidad, las mutaciones
se definen como cambios en la secuencia o en el número de nucleótidos
en el ácido nucleico de una célula o de un organismo. Las mutaciones
de punto pueden ocurrir en forma de sustituciones de un nucleótido por
otro, deleciones o adiciones de nucleótidos. Las mutaciones que ocurren
en los gametos -o en las células que originan gametos- se transmiten
a generaciones futuras. Las mutaciones que ocurren en las células somáticas
sólo se transmiten a las células hijas que se originan por mitosis
y citocinesis.
Otros cambios en la secuencia
de aminoácidos de una proteína pueden ser resultado de la deleción
o la adición de nucleótidos dentro de un gen. Cuando esto ocurre,
el marco de lectura del gen puede desplazarse. Esto, en general, da como resultado
la síntesis de una proteína completamente nueva. Los "corrimientos
del marco de lectura" casi invariablemente llevan a proteínas defectuosas.
La deleción o la adición de nucleótidos dentro de un gen lleva a cambios en la proteína producida. La molécula de DNA original, el mRNA transcripto a partir de ella y el polipéptido resultante se muestran en a). En b) vemos el efecto de la deleción de un par de nucleótidos (T-A), en donde indica la flecha. El marco de lectura del gen se altera y aparece una secuencia diferente de aminoácidos en el polipéptido. En c), la adición de un par de nucleótidos (C-G en rosa) da como resultado un cambio semejante.
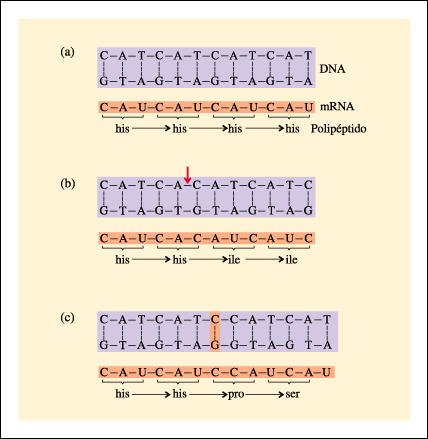
La deleción o la adición de nucleótidos dentro de un gen lleva a cambios en la proteína producida.
Origen y universalidad del código
genético
El código genético
es universal. Sin embargo, existen excepciones. En algunos casos, un codón
de terminación pasa a ser usado para codificar un aminoácido;
en otros casos, un codón es reasignado a un aminoácido diferente
del original.
Ejemplos del primer caso se han observado en la bacteria Mycoplasma, en el ciliado Paramecium y en las mitocondrias de varios organismos.
Ejemplos del segundo caso han
sido encontrados en las mitocondrias y en el núcleo de varias especies
de levaduras.
De todas maneras, aunque existen desviaciones del código universal, éstas
son sólo variaciones menores. La casi universalidad del código
indica un origen único. Si bien las variaciones ocasionales muestran
que las asignaciones de codones pueden cambiar, estos cambios ocurren muy raramente;
aunque en la evolución temprana del código, estos cambios podrían
haber sido más frecuentes.


